
2.2.2.2. Các vấn đề hồi quy tuyến tính¶
Giả sử dữ liệu đầu vào bao gồm (n ) quan sát, là các cặp biến đầu vào và biến đích (( mathbf {x} _1, y_1), ( mathbf {x} _2, y_2), dấu chấm, ( mathbf {x} _n, y_n) ). Hồi quy mô hình sẽ tìm kiếm một vectơ ước lượng ( mathbf {w} = [w_0, w_1, dot, w_p] ) để giảm thiểu hàm mất mát của dạng mse:
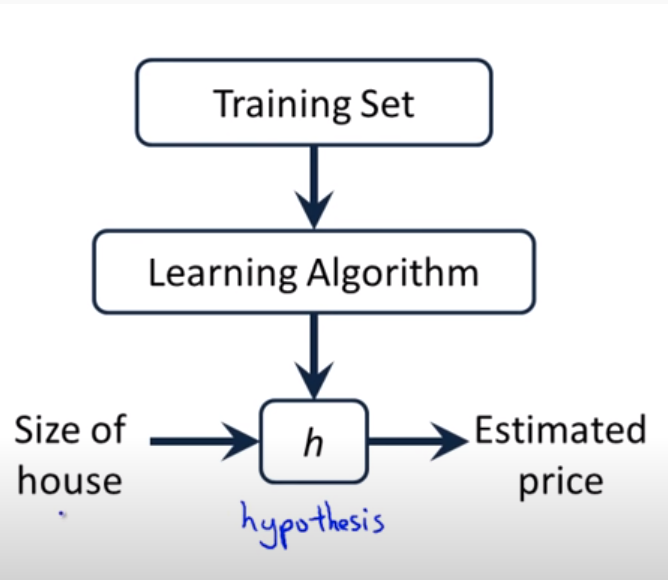
Nhắc lại khái niệm về hàm mất mát. Trong mô hình học có giám sát của máy học, từ dữ liệu đầu vào, thông qua thuật toán học, chúng tôi sẽ đề xuất một hàm giả thuyết (h ) (hàm giả thuyết) để mô tả mối quan hệ dữ liệu giữa biến đầu vào và biến đích.
Bạn Đang Xem: Deep AI KhanhBlog
Xem Thêm : Đá Onyx là gì? Ưu nhược điểm của đá Onyx
Hình 1: Nguồn: andrew ng – Hồi quy tuyến tính của một biến. Từ quan sát đầu vào ( mathbf {x} _i ), sau khi nhập hàm giả thuyết (h ), chúng tôi nhận được giá trị dự đoán ( hat {y} ) trong đầu ra. Ký tự (h ) trong tên hàm là viết tắt của từ giả thuyết, có nghĩa là giả thuyết, một khái niệm mang tính thời gian trong thống kê. Để mô hình chính xác hơn, sai số giữa giá trị dự đoán ( hat {y} ) và giá trị trung thực cơ bản (y ) phải nhỏ hơn. Vậy làm cách nào để đo mức độ sai số nhỏ giữa ( hat {y} ) và (y )? Các thuật toán học có giám sát trong học máy sử dụng một hàm mất mát để xác định lỗi này.
Hàm mất mát cũng là mục tiêu tối ưu khi đào tạo mô hình. Dữ liệu đầu vào ( mathbf {x} ) và (y ) được coi là cố định và các biến của bài toán tối ưu hóa là các giá trị trong vectơ ( mathbf {w} ).
Giá trị của hàm mất mát mse là giá trị trung bình của tổng bình phương còn lại. Phần dư là chênh lệch giữa giá trị thực tế và giá trị dự đoán. Việc giảm thiểu hàm tổn thất nhằm mục đích làm cho giá trị dự đoán ít khác với giá trị thực tế, còn được gọi là giá trị cơ bản. Chúng tôi không thực sự biết vectơ hệ số ( mathbf {w} ) là gì cho đến khi mô hình được đào tạo. Chúng ta chỉ có thể giả định dạng của hàm dự đoán (phương trình tuyến tính trong trường hợp này) và các hệ số hồi quy tương ứng. Do đó, mục đích của việc giảm thiểu hàm mất mát là tìm các tham số phù hợp nhất ( mathbf {w} ) để tổng quát hóa mô tả của biến đầu vào ( mathbf {x)} ) và biến đích ( mathbf {y} ) trên tập huấn luyện.
Xem Thêm : Acquisition Là Gì? Những Thương Vụ Acquisition Khách Sạn Nổi Tiếng Tại Việt Nam
Tuy nhiên, mối quan hệ này thường không mô tả được các quy luật chung của dữ liệu, do đó dẫn đến trang bị quá mức. Một trong những lý do tại sao một mô hình không thể tổng quát hóa là mô hình đó quá phức tạp. Như thể hiện trong hình bên dưới, khi kích thước của các hệ số bậc cao trong mô hình hồi quy có xu hướng lớn thì độ phức tạp càng cao:

Hình 2: Hình này cho thấy độ phức tạp của mô hình như một hàm của thứ tự. Phương trình phức tạp nhất là phương trình bậc ba: (y = w_0 + w_1 x + w_2 x ^ 2 + w_3 x ^ 3 ). Trong chương trình thpt, chúng ta biết rằng một phương trình bậc ba thông thường sẽ có 2 điểm uốn và phức tạp hơn một phương trình bậc hai chỉ có 1 điểm uốn. Khi (w_3 rightarrow 0 ) thì phương trình bậc hai hội tụ về phương trình bậc hai: (y = w_0 + w_1 x + w_2 x ^ 2 ), lúc này phương trình là parabol và độ phức tạp giảm xuống. Tiếp tục kiểm soát độ lớn để (w_2 rightarrow 0 ) trong phương trình bậc hai, chúng ta sẽ nhận được một đường thẳng có dạng (y = w_0 + w_1 x ) với độ phức tạp thấp nhất.
Vì vậy, việc kiểm soát kích thước của các công cụ ước tính, đặc biệt là các công cụ có bậc cao hơn, sẽ giúp giảm độ phức tạp của mô hình và do đó khắc phục được việc trang bị quá mức. Vậy làm thế nào để kiểm soát chúng, hãy xem các chương sau.
Nguồn: https://anhvufood.vn
Danh mục: Kinh Nghiệm








